After a discussion on the Continual Learning Slack (continualai.slack.com join us !), it looks like the use of task labels is not always clear in continual learning (CL) approaches. So I decided to create a small post-blog resuming the discussion and proposition.
First, what is a task label?
The task label is an abstract representation of a learning experience. In continual learning, the learning algorithms learn from a data distribution that is not static (I will call the full continual learning process the “continuum”), the task label allows splitting this continuum into smaller pieces of learning experiences. So us humans, decide to split the learning continuum into pieces we call tasks. The task label is the ID we give to those subparts. It is important to notice that it is completely arbitrary and only depends on the point of view of the continual learning setting creator.
However, we can define a few particular use cases of the task label that could help to disentangle different kinds of continual learning scenario:
1- Continual Learning Scenarios
We can described three different use cases of the task labels [1].
- *Single-Incremental-Task (SIT)*:
Whatever happens, the task label is always the same, there is only one task.
- *Multi-Task (MT)* :
There are several tasks that are learned only once, the task label will never indicate two times the same task.
- *Multi-Incremental-Task (MT)* :
There are several tasks that are learned but tasks can be learned several times, the task label can indicate two times the same task.
This classification helps to distinguish use cases of the task label but it does not consider the assumption made on the task labels concerning the variation in the data distribution: i.e. the concept drift.
2- Task labels and concept drift
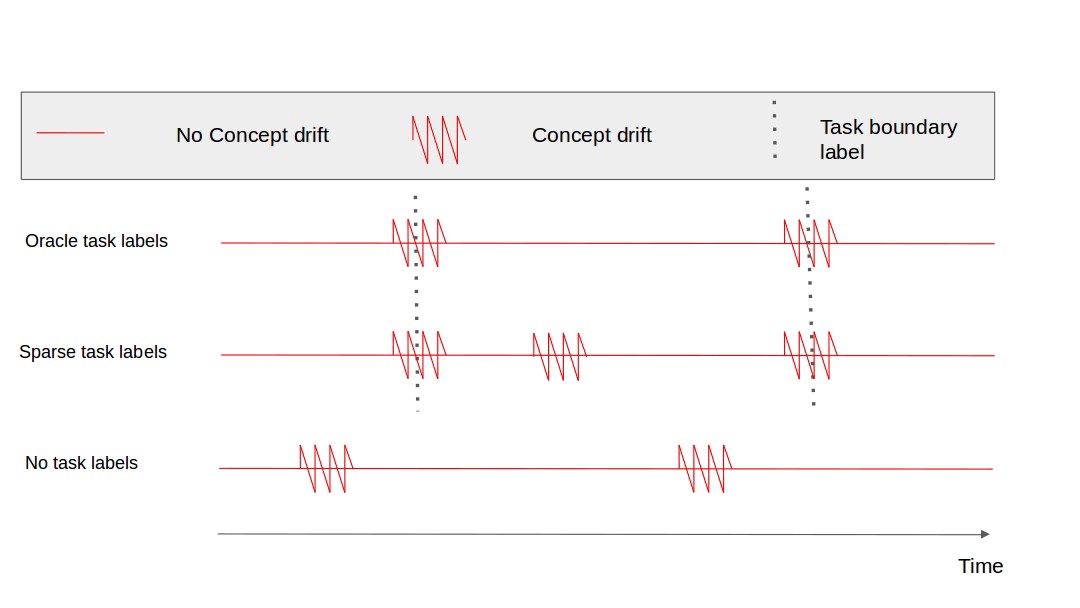
The task labels are virtual wall we put to divide our learning curriculum, however, depending on the setting, the assumptions made on the task labels are different. In the following figure, are presented the three different cases.
 <\br>
Task labels and concept drift: the different settings
<\br>
Task labels and concept drift: the different settings
*No task label:*
The data stream is provided to the learning algorithm without any supplementary information. It could be similar to classical machine learning but the data distribution is not assumed static and catastrophic forgetting may happen as soon as the distribution change (when concept drift happens). This would be the setting of a completely autonomous agent that should learn from a stream of data, therefore close to real-life settings but hard to solve and generalize.
*Sparse task labels:*
As the “No task label” case, this scenario is quite close to a real-life setting. The algorithms learn autonomously but from time to time, it gets a new label when data distribution changes. Nevertheless, the data distribution might also change while no new task label is provided. The change in the data distribution can be called “concept drift”, described in [5].
*Oracle task labels:*
This is the case of most continual learning existing approaches nowadays. Every concept drift in the data distribution is indicated by the task label. This is a particularly convenient case because since the algorithm exactly knows when the distribution change, it can better handle risks of forgetting.
So here, we categorize the different hypotheses made on the task label. However, there is one more distinction that can be done concerning the task labels: its availability.
3- Task label availability
When a task label is provided, we should know it which occasion the algorithm has access to it. We define then two cases:
The Learning Task Label [4]
This case can also be referred to as “Domain Incremental Learning” [2]. It is also described in [3] (in Section 3.C).
In this case, we consider that we provide task labels to help the algorithms to learn but at test time, the algorithms will make its decision autonomously. This is the case, for class incremental learning. The algorithms are aware when a new class arises but at test time, the algorithms have no information about data a should find the right class.
The Permanent Task Label [4]
This case has also been described in [2] as “Task-Incremental Learning”
In this case, the task label is used for learning as well as for inference. This is the case in the algorithms called “multi-head”, where an output layer (a head) is specific to a task. At test time the algorithms should know which head to use and need then the task label. This scenario makes training greatly easier (a trivial solution is a model per task), however, this scenario is considered in the CL community as not really related to what continual learning aims at solving. CL aims at developing algorithms that learn continually and can be deployed autonomously after. If the model needs a label at deployment it is not autonomous.
 task labels available vs task label unavailable : visualization
task labels available vs task label unavailable : visualization
So to resume the order of difficulty for training an algorithm:
No task label > Sparse task label » Oracle task label
And
Learning task label » Permanent Task Label
The particular difficulty of “No task label” and “Sparse task label” is to detect data distribution drift to prevent forgetting. “Oracle task label” cases target essentially the forgetting problems. “Oracle task label” combined with “Permanent Task Label” might face forgetting depending on how it is implemented but the trivial solution of one model per task does not face it.
One could think about “special case” not mention in this blog post such as “label only available at test time and not for learning” but the idea of task label is intrinsically linked to learning. Task labels available only for testing does not make much sense in my opinion :)
A framework similar to what is presented in this article is proposed in [4] to present continual learning approaches and describes how the task label is used. Anyway, to understand clearly the use of a task label it is fundamental to understand the CL scenario, the assumptions and the availability of the task label.
If you want to discuss/comment on the different use of task labels, don’t hesitate to come to the continualAI slack!
Timothée LESORT PhD Candidate @ Thales / Ensta-Paris Board member and co-founder of ContinualAI, https://www.continualai.org/
Thanks to Vincenzo Lomonaco and Massimo Caccia for helping me in the realization of this article.
[1] “Continuous Learning in Single-Incremental-Task Scenarios”, Davide Maltoni, Vincenzo Lomonaco, Neural Networks, 2019 [2] “Three scenarios for continual learning”, Gido M. van de Ven, Andreas S. Tolias [3] “Towards Robust Evaluation of Continual Learning” Sebastian Farquhar, Yarin Gal [4] “Continual Learning for Robotics: Definition, Framework, Learning Strategies, Opportunities and Challenges”, Timothée Lesort, Vincenzo Lomonaco, Andrei Stoian, Davide Maltoni, David Filliat, Natalia Díaz-Rodríguez [5] “Incremental learning algorithms and applications”, Alexander Gepperth and Barbara Hammer, ESANN 2016